In this post I’ll show a way to do quantile regression on a bounded unit interval. The Vasicek distribution is an alternative distribution for beta regressions and is described in Mazucheli et al. (2022). The Vasicek distribution is given as
\[
\begin{aligned}
f(y \mid \alpha, \theta) &= \sqrt{\frac{1 - \theta}{\theta}} \exp \bigg\{\frac{1}{2} \bigg[\Phi^{-1}(y)^2 -
\bigg(\frac{\Phi^{-1}(y) \sqrt{1 - \theta} - \Phi^{-1}(\alpha)}{\sqrt{\theta}} \bigg)^2
\bigg\} \\
F(y \mid \alpha, \theta) &= \Phi \bigg( \frac{\Phi^{-1}(y) \sqrt{1 - \theta} - \Phi^{-1}(\alpha)}{\sqrt{\theta}} \bigg) \\
Q(\tau \mid \alpha, \theta) &= F^{-1}(\tau \mid \alpha, \theta) = \Phi \bigg( \frac{\Phi^{-1}(\alpha) + \Phi^{-1}(\tau) \sqrt{\theta}}{\sqrt{1 - \theta}} \bigg)
\end{aligned}
\] where \(0 < (y, \alpha, \theta, \tau) < 1\) and \(\Phi\) and \(\Phi^{-1}\) are the standard normal CDF and QF respectively. The mean of the distribution is \(\operatorname{E}(Y) = \alpha\) and \(\operatorname{Var}(Y) = \Phi_2(\Phi^{-1}(\alpha), \Phi^{-1}(\alpha), \theta)\) where \(\Phi_2\) is the bivariate standard normal CDF.
In the paper they reparameterize the mean in terms of the \(\tau\)-th quantile as \[
\alpha = h^{-1}(\mu) = \Phi(\Phi^{-1}(\mu)\sqrt{1 - \theta} - \Phi^{-1}(\tau)\sqrt{\theta}).
\] Given this reparmeterization the log-likelihood is \[
\begin{aligned}
\ell( \mu, \theta \mid y, \tau) = \;& \frac{n}{2}\log\bigg(\frac{1 - \theta}{\theta} \bigg) - \frac{\Phi^{-1}(y)^\top \Phi^{-1}(y)}{2} - \\
& \frac{1}{2\theta} \sum_{i=1}^{n} \bigg(\sqrt{1 - \theta}\bigg[\Phi^{-1}(y_i) - \Phi^{-1}(\mu) \bigg] + \sqrt{\theta}\Phi^{-1}(\tau) \bigg)^2
\end{aligned}
\] The log-likelihood may be written in Stan as:
real vasicek_quantile_lpdf(vector y, real theta, vector mu, real tau) {if (tau <=0|| tau >=1) reject("tau must be between 0 and 1 found tau = ", tau);if (theta <=0|| theta >=1) reject("theta must be between 0 and 1 found theta = ", theta);int N =num_elements(y);real lpdf =0.5* N * (log1m(theta) -log(theta));vector[N] qnorm_mu =inv_Phi(mu);real qnorm_tau =inv_Phi(tau);vector[N] qnorm_y =inv_Phi(y);vector[N] qnorm_alpha =-sqrt(theta) * qnorm_tau + qnorm_mu *sqrt(1- theta);return lpdf +0.5*dot_self(qnorm_y) -0.5*sum( (sqrt(1- theta) * qnorm_y - qnorm_alpha)^2/ theta); }
The authors provided an R package vasicekreg where we can check if it results in the same log-likelihood,
library(cmdstanr)library(vasicekreg)source("expose_cmdstanr_funs.R")x <-rVASIQ(n =1, mu =0.50, sigma =0.69, tau =0.50)expose_cmdstanr_functions("vasicek.stan", expose_to_global_env = T)
Warning in readLines(temp_cpp_file): incomplete final line found on
'/var/folders/dm/p14hjty57hndjp4f4n_y1dz00000gn/T//RtmpX7Wede/model-305333dd1948.cpp'
stan_lpdf <-vasicek_quantile_lpdf(x, theta =0.69, mu =0.5, tau =0.5)r_lpdf <-dVASIQ(x, mu =0.5, sigma =0.69, log = T)all.equal(stan_lpdf, r_lpdf)
We can update the code to run multiple quantiles which is the same as running the model for each quantile. In Stan, we can run the same model multiple times or we do the loop, as I show below, inside the program and pass a vector of \(\tau\)’s in as data.
Aki Veharti correctly noted that the increase in the number of parameters will reduce the step size and increase the number of steps. If you have lots of data then it may make more sense to run each \(\tau\) independently.
We see that the sampler must take smaller steps and increase the number of leapfrog integrations.
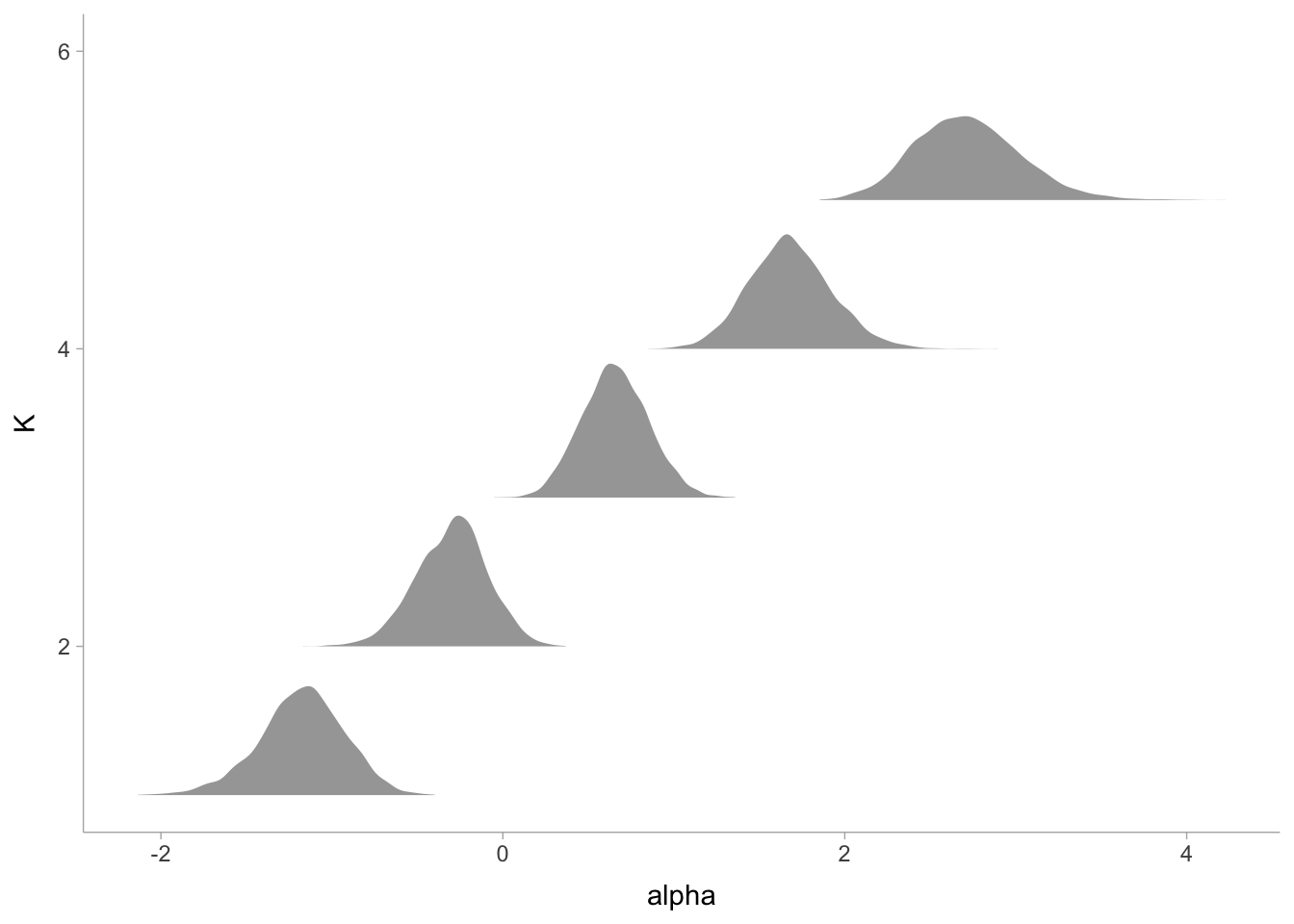
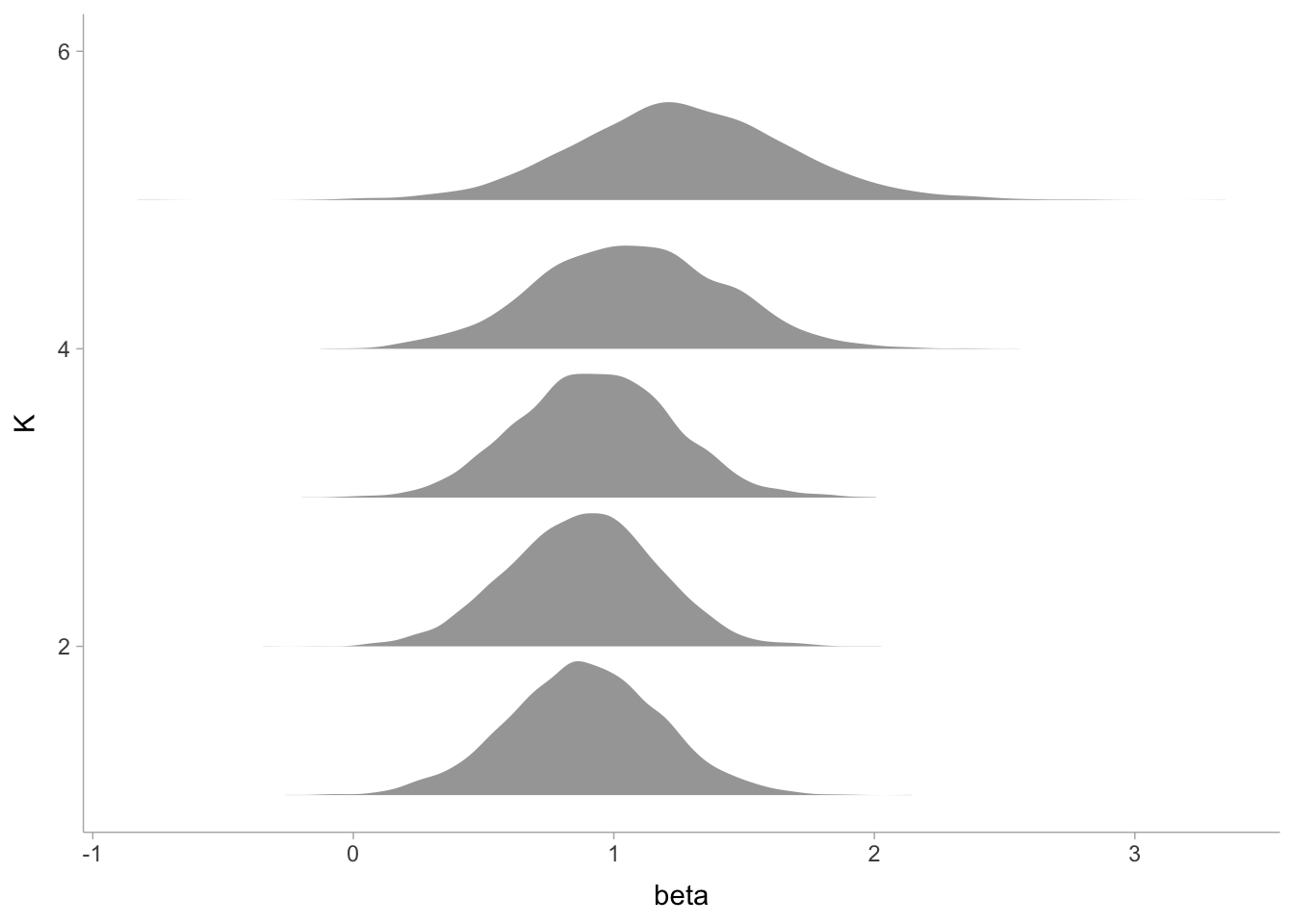
Lastly, we can plot the effects. Here are the intercepts and beta coefficients
library(posterior)library(tidybayes)library(ggplot2)source("../../R/theme_blog.R")fit_stan_vector |>spread_draws(alpha[K]) |>ggplot(aes(y = K, x = alpha)) +stat_slabh(fill = blog_colors$teal) +theme_blog() +labs(title ="Posterior distribution of alpha by quantile")
fit_stan_vector |>spread_draws(beta[K]) |>ggplot(aes(y = K, x = beta)) +stat_slabh(fill = blog_colors$purple) +theme_blog() +labs(title ="Posterior distribution of beta by quantile")
In my next post, quantile regression post I’ll show various ways to represent a quantile regression in Stan where the outcome, however, is continuous on the real line.
functions {real vasicek_quantile_lpdf(vector y, real theta, vector mu, real tau) {if (tau <=0|| tau >=1) reject("tau must be between 0 and 1 found tau = ", tau);if (theta <=0|| theta >=1) reject("theta must be between 0 and 1 found theta = ", theta);int N =num_elements(y);real lpdf =0.5* N * (log1m(theta) -log(theta));vector[N] qnorm_mu =inv_Phi(mu);real qnorm_tau =inv_Phi(tau);vector[N] qnorm_y =inv_Phi(y);vector[N] qnorm_alpha =-sqrt(theta) * qnorm_tau + qnorm_mu *sqrt(1- theta);return lpdf +0.5*dot_self(qnorm_y) -0.5*sum( (sqrt(1- theta) * qnorm_y - qnorm_alpha)^2/ theta); }}data {int<lower=0> N;vector[N] y;vector[N] x;int<lower=1> K;vector<lower=0, upper=1>[K] tau;} parameters {vector[K] alpha;vector[K] beta;vector[K] sigma;} model { alpha ~ normal(0, 4);beta~ normal(0, 4); sigma ~ normal(0, 2);for (i in1:K) y ~ vasicek_quantile(inv_logit(sigma[i]), inv_logit(alpha[i] +beta[i] * x), tau[i]);}
References
Mazucheli, Josmar, Bruna Alves, Mustafa Ç. Korkmaz, and Víctor Leiva. 2022. “Vasicek Quantile and Mean Regression Models for Bounded Data: New Formulation, Mathematical Derivations, and Numerical Applications.”Mathematics 10 (9). https://doi.org/10.3390/math10091389.