Quantile regressions are relatively new in the Bayesian literature first appearing in Yu and Moyeed (2001) who described an asymmetric Laplace distribution to estimate the conditional quantiles. This post is going to show the asymmetric Laplace and the augmented version. In part II I will show the score likelihood method.
functions{real q_loss(real q, vector u){return0.5*sum(abs(u) + (2* q -1) * u);}real ald_lpdf(vector y, real q, real sigma, vector q_est){int N =num_elements(y);return N * (log(q) +log1m(q) -log(sigma)) - q_loss(q, y - q_est) / sigma;}}data {int N; // Number of observationint P; // Number of predictorsreal<lower=0, upper=1> q;vector[N] y; // Response variable sortedmatrix[N, P] x;}parameters {vector[P] beta;real<lower=0> sigma;}model {beta~ normal(0, 4); sigma ~ exponential(1); y ~ ald(q, sigma, x *beta);}
Let’s compare the 5th percentile to the Brq R package
y = ImmunogG$IgGx = ImmunogG$AgeX=cbind(x, x^2)fit =Brq(y ~ X , tau=0.05,runs=2000, burn=1000)print(summary(fit))
Call:
Brq.formula(formula = y ~ X, tau = 0.05, runs = 2000, burn = 1000)
tau:[1] 0.05
Estimate L.CredIntv U.CredIntv
Intercept 0.6201064 0.1113146 1.03475824
Xx 1.2991424 0.8962901 1.68272470
X -0.1550870 -0.2317421 -0.08612944
Using the covariates for extra information
In Lee et al. (2022) they detail a Bayesian approach to the envelope quantile regression. In all honesty, I briefly skimmed the paper and gathered that by adding a regression on the covariates and using this information in the asymmetric Laplace can help identification. This isn’t a recreation of their method but a quick detour to see if a simplified version of what they do increases ESS.
The idea is that we use the variability in the covariance of the regressors to help identify the coefficients on the ALD regression. I now have to separate out the intercept into \(\alpha\).
Show the code
functions{real q_loss(real q, vector u){return0.5*sum(abs(u) + (2* q -1) * u);}real ald_lpdf(vector y, real q, real sigma, vector q_est){int N =num_elements(y);return N * (log(q) +log1m(q) -log(sigma)) - q_loss(q, y - q_est) / sigma;}}data {int N; // Number of observationint P; // Number of predictorsreal<lower=0, upper=1> q;vector[N] y; // Response variable sortedmatrix[N, P] x;}transformed data {array[N] vector[P] X;for (i in1:P) { X[:, i] =to_array_1d(x[:, i]); }}parameters {vector[P] eta;real<lower=0> sigma;vector[P] mu;cholesky_factor_corr[P] L;vector<lower=0>[P] gamma;real alpha;}transformed parameters {vector[P] beta= eta .*gamma;}model { eta ~ normal(0, 4); sigma ~ exponential(1); y ~ ald(q, sigma, alpha + x *beta); alpha ~ normal(0, 4);gamma~ exponential(1); mu ~ normal(0, 4); X ~ multi_normal_cholesky(mu, diag_pre_multiply(gamma, L));}
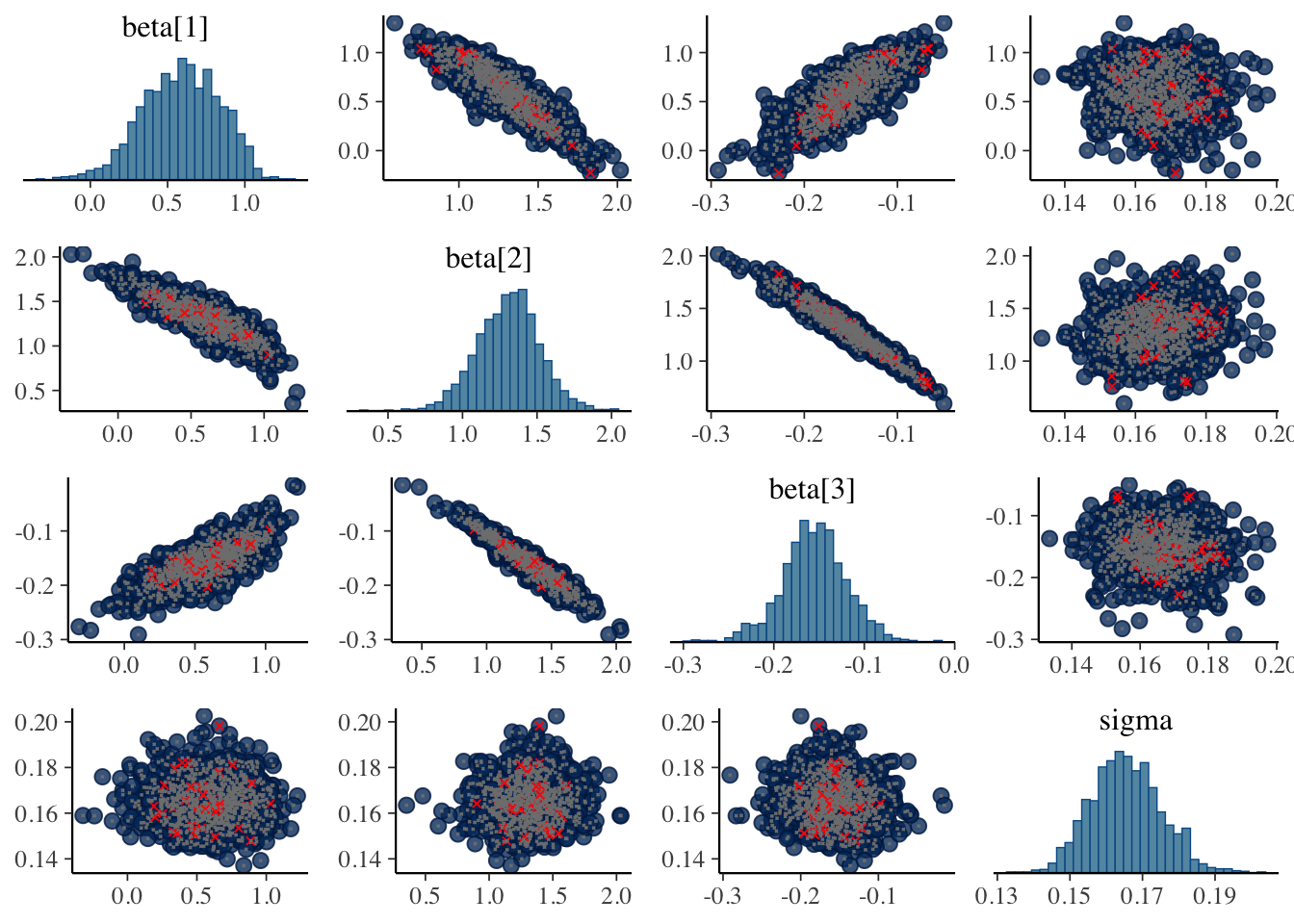
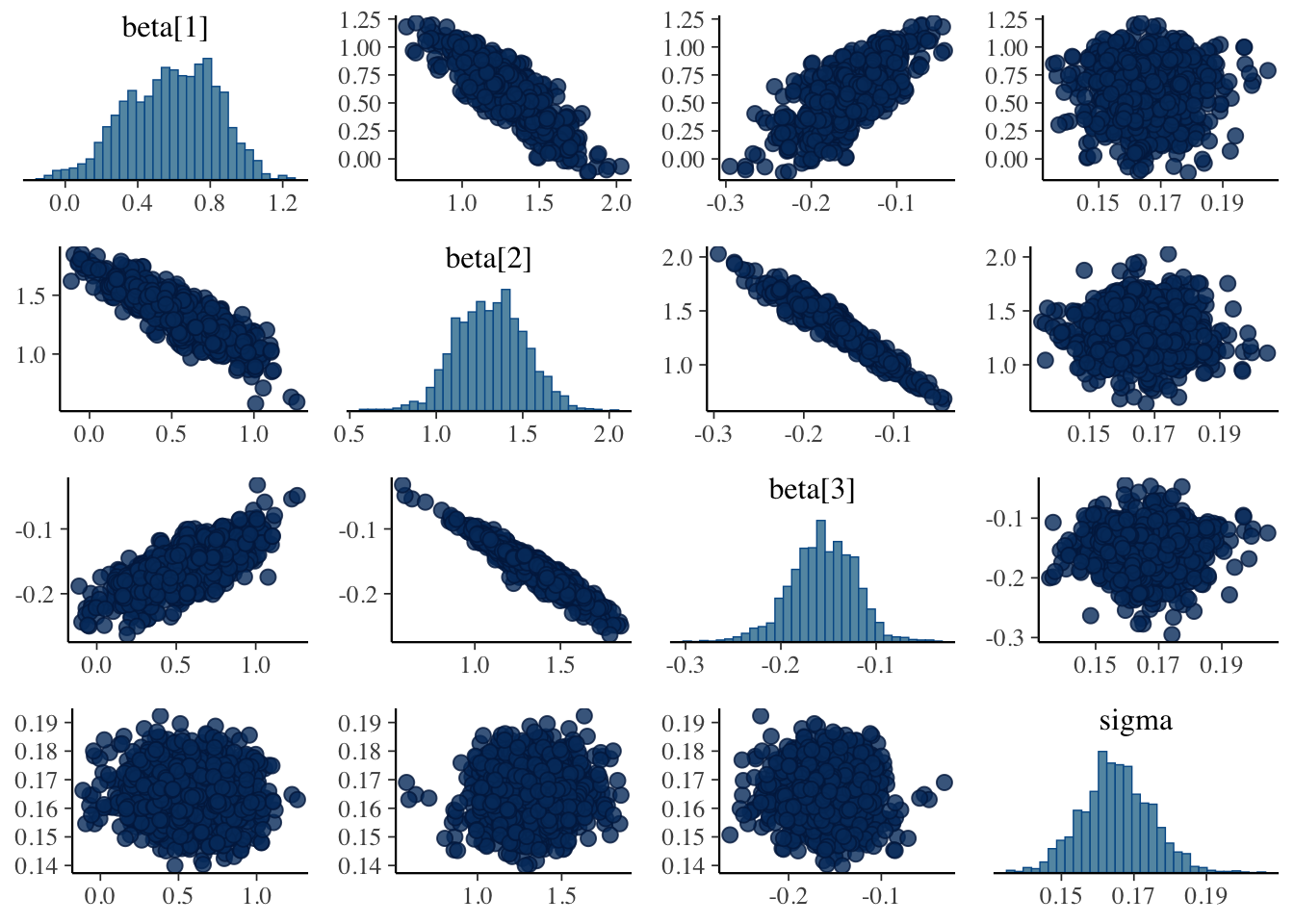
Ouch! Divergences. Although the parameter estimates look comparable. Let’s inspect the pairs plots between the augmented version and the asymmetric Laplace.
Show the code
library(bayesplot)
This is bayesplot version 1.15.0
- Online documentation and vignettes at mc-stan.org/bayesplot
- bayesplot theme set to bayesplot::theme_default()
* Does _not_ affect other ggplot2 plots
* See ?bayesplot_theme_set for details on theme setting
The pairs plots don’t appear to show the divergence originating be due to beta or sigma. It’s most likely the augmentation variables z. As I’m up for time on this, I’d be curious to test out alternative specifications or see if anyone has encountered these issues with the augmented version and found a solution.
Try Student T
Warning
The Student T won’t result in the same posterior and is likely not ALD. However, it approaches a normal distribution with increasing \(\nu\).
Let’s use the student_t with \(\nu = 30\)
Show the code
data {int N; // Number of observationint P; // Number of predictorsreal<lower=0, upper=1> q;vector[N] y; // Response variable sortedmatrix[N, P] x;}transformed data {real theta = (1-2* q) / (q * (1- q));real tau =sqrt(2/ (q * (1- q)));}parameters {vector[P] beta;vector<lower=0>[N] z;real<lower=0> sigma;}model {beta~ normal(0, 2); sigma ~ exponential(1);// Data Augmentation z ~ exponential(1); y ~ student_t(30, x *beta+ sigma * theta * z, tau *sqrt(z) * sigma);}